Speech Generation
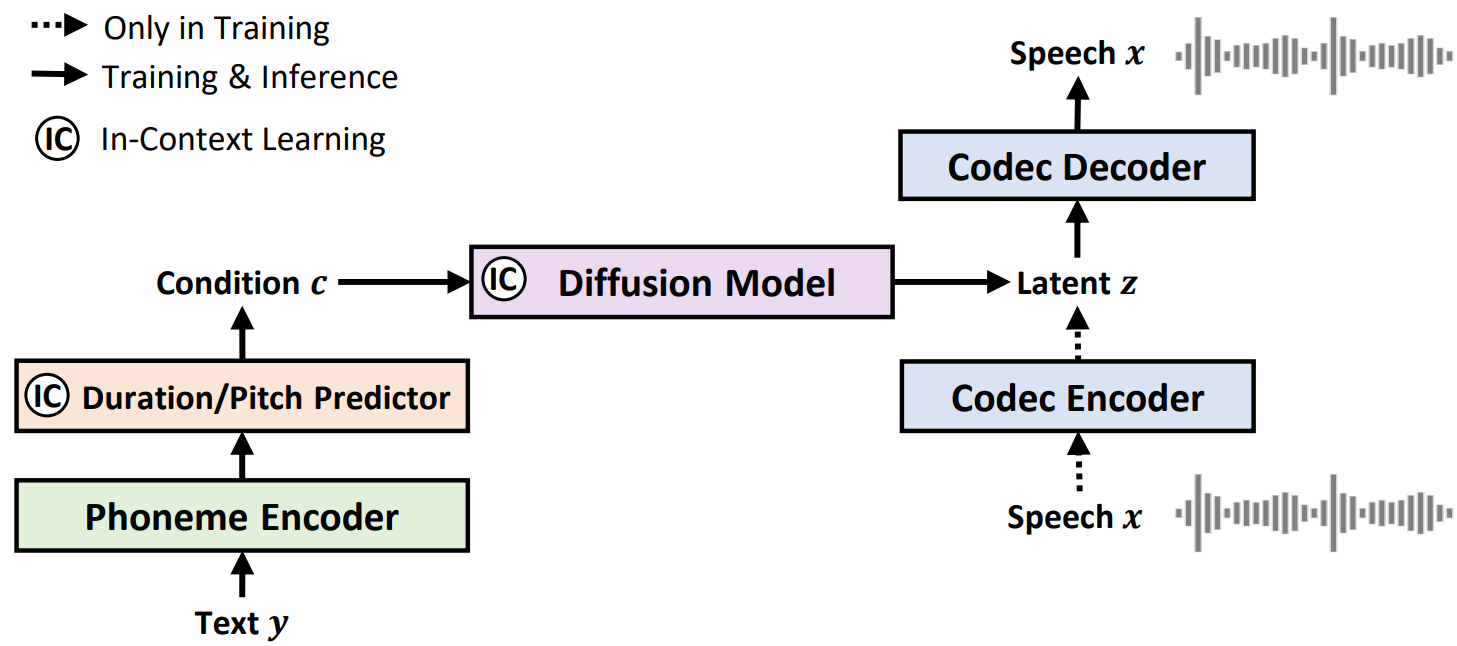
NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers, arXiv 2023
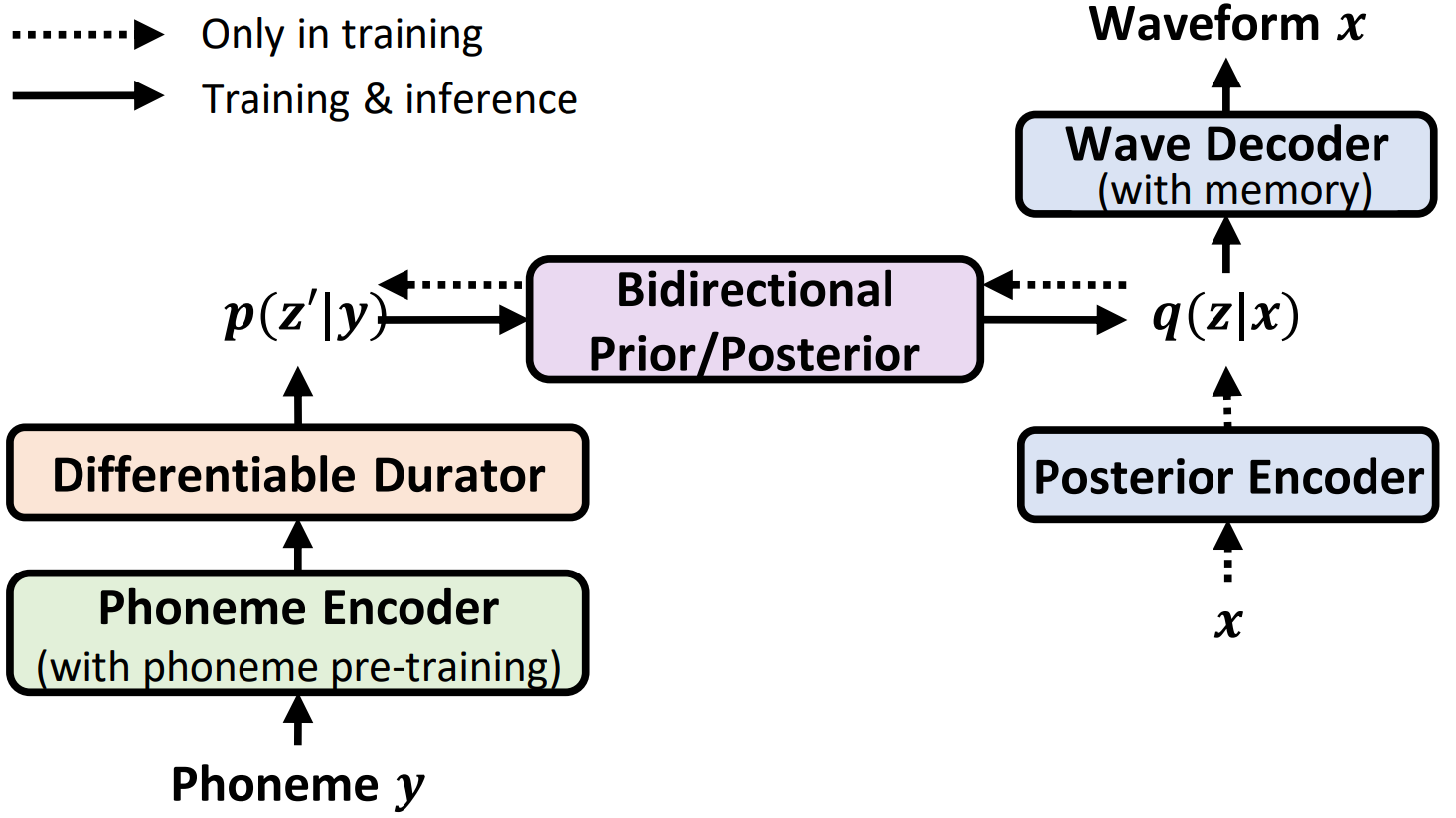
NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality, arXiv 2022
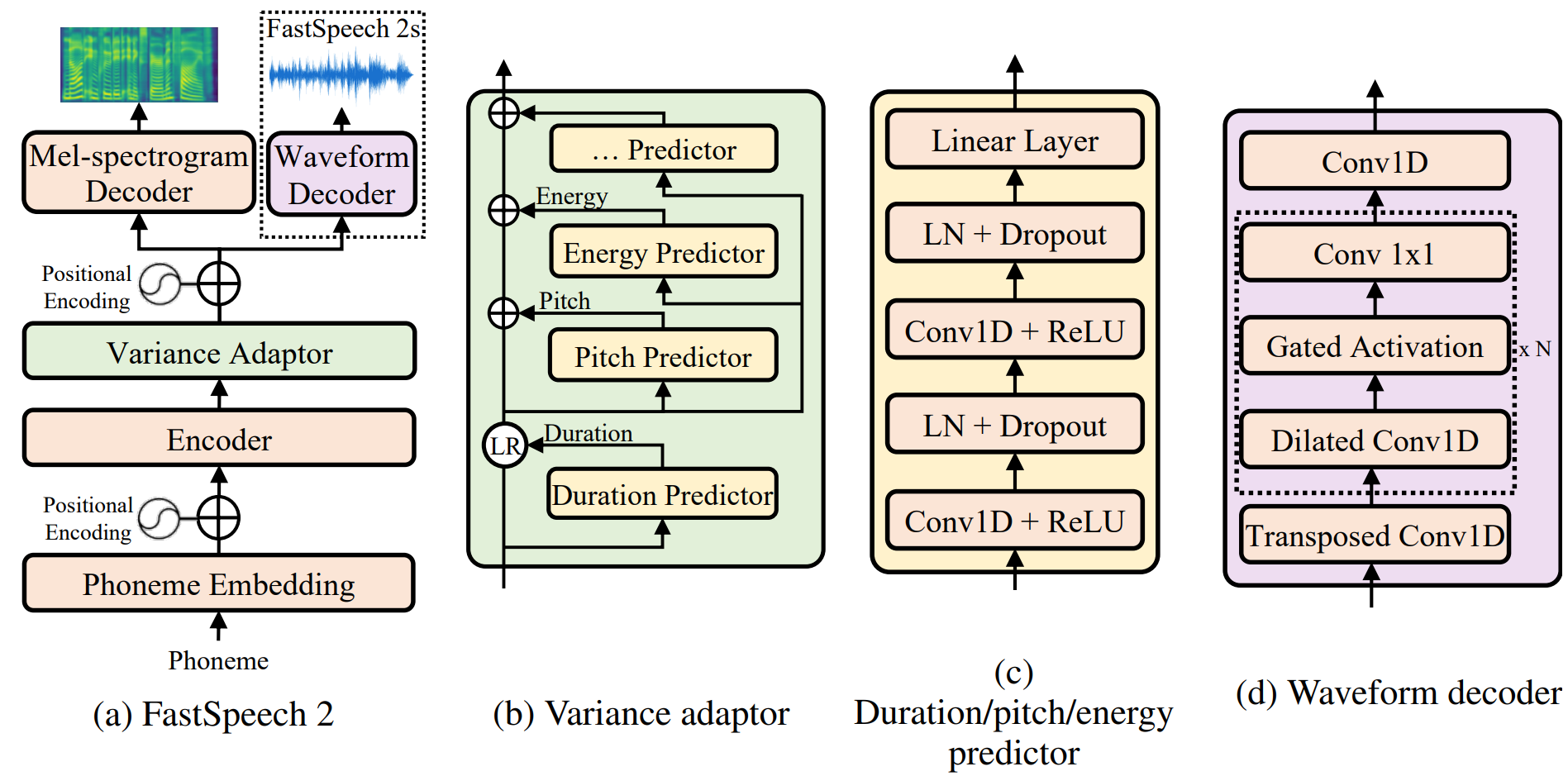
FastSpeech 2: Fast and High-Quality End-to-End Text to Speech, ICLR 2021
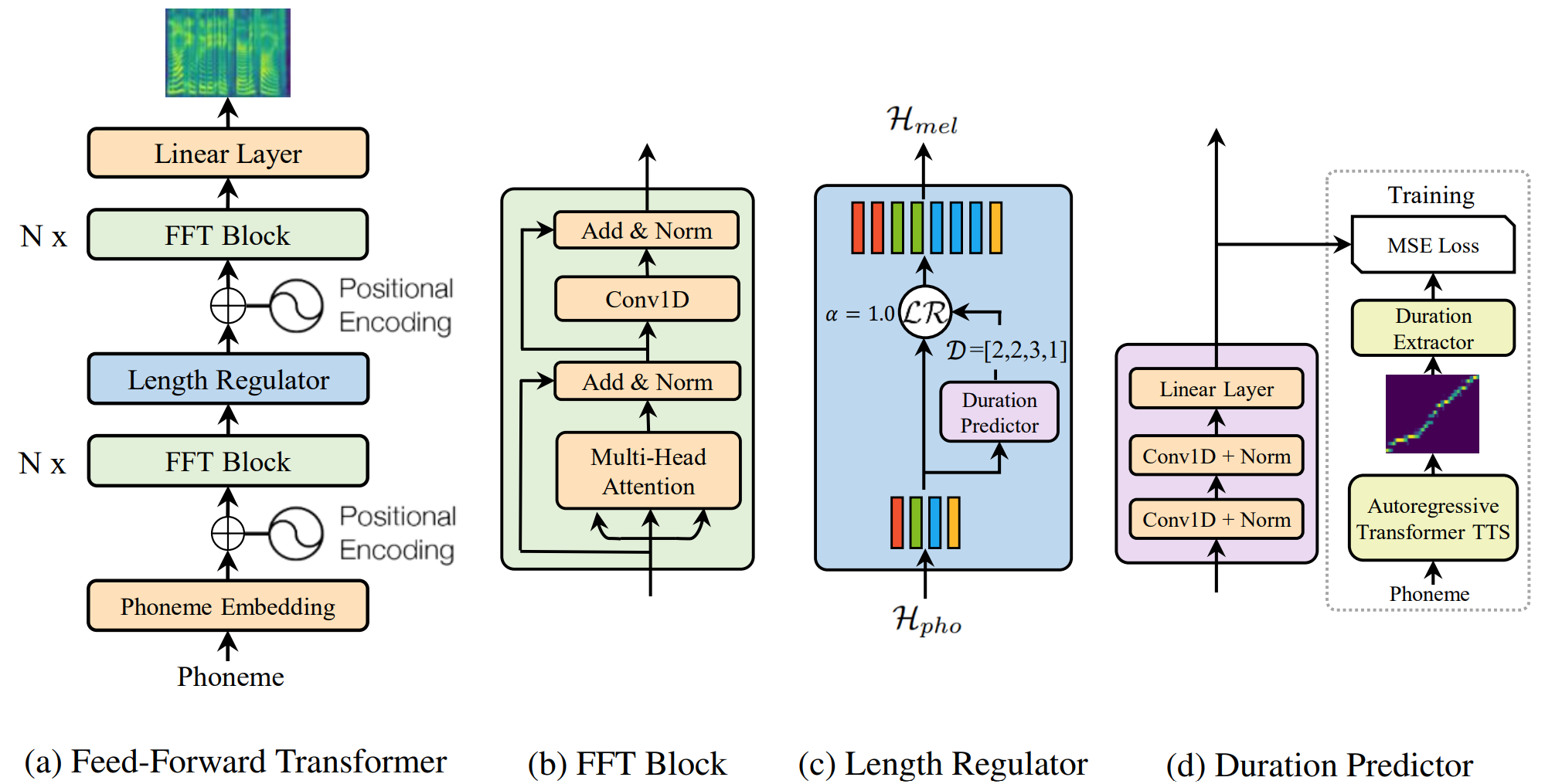
FastSpeech: Fast, Robust and Controllable Text to Speech, NeurIPS 2019

PriorGrad: Acoustic Model

PriorGrad: Vocoder
PriorGrad: Improving Conditional Denoising Diffusion Models with Data-Dependent Adaptive Prior, ICLR 2022
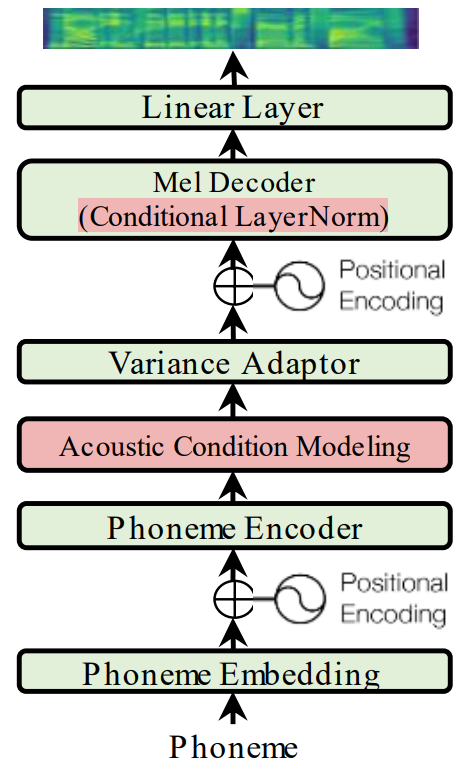
AdaSpeech: Adaptive Text to Speech for Custom Voice, ICLR 2019
AdaSpeech 2: Adaptive Text to Speech with Untranscribed Data, ICASSP 2021
AdaSpeech 3: Adaptive Text to Speech for Spontaneous Style, INTERSPEECH 2021
AdaSpeech 4: Adaptive Text to Speech in Zero-Shot Scenarios, INTERSPEECH 2022
DelightfulTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2021, Blizzard Challegnge 2021
DelightfulTTS 2: End-to-End Speech Synthesis with Adversarial Vector-Quantized Auto-Encoders, INTERSPEECH 2022
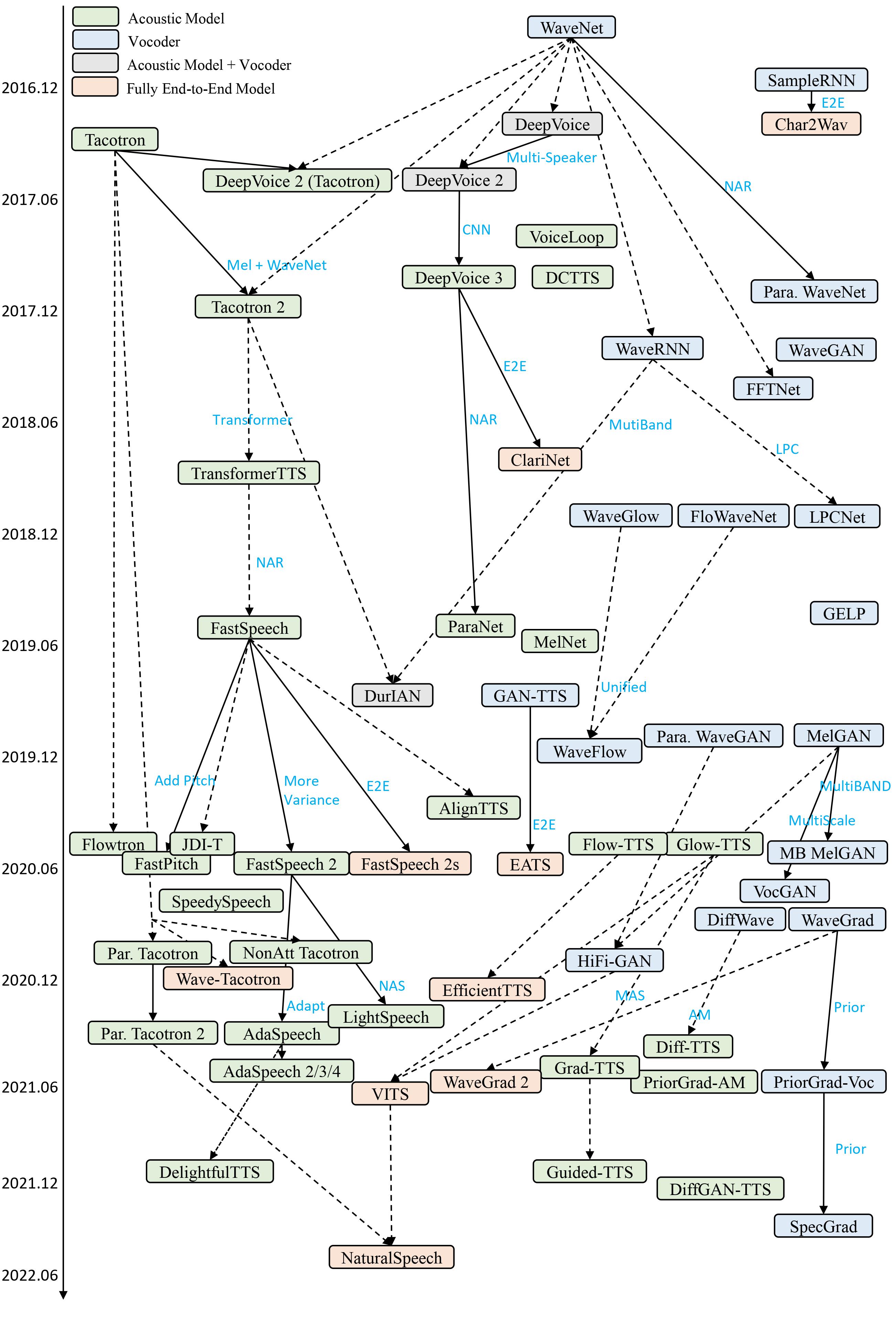
A Survey on Neural Speech Synthesis, arXiv 2021
Tutorial on Speech Synthesis at ISCSLP 2021, IJCAI 2021, ICASSP 2022, INTERSPEECH 2022
NeuralSpeech: an opensource repo on speech
